Binomial Mixture Model with Expectation Maximum (EM) Algorithm

Binomial distribution is a probability distribution that is commonly encountered. For example, the number of heads (n) one gets after flipping a coin N times follows the binomial distribution. If the coin is symmetric on the head and tail sides, the chance of getting a head after one time of flipping is θ=0.5, the expression for the Binomial distribution is

where the number of combinations for selecting n items out of N items is

For another example, in Bioinformatics, it is usually assumed that the number of errors made in DNA or RNA sequencing follows the Binomial Distribution (e.g. Rabadan et al. 2015). Imagine a segment of DNA is being sequenced in an equipment (for more information about the current sequencing technique, you may refer to this youtube video), and at the 50th position of this segment, the nucleotide is a Cytosine (C for short). The sequencing equipment generates N reads of this particular position and the probability of mistaking Cytosine (C for short) for Adnine (A for short) is θ, then the probability of making n such mistakes follows the Binomial distribution, Bino(n|N,θ). In reality, the probability of a certain mistake (e.g. C to A) is not the same across all positions in a DNA segment. In other words, there may exist more than one θ’s for the same type of mistake like a C-to-A mistake. In this situation, one needs to consider a Binomial Mixture Model. Below, we use flipping coins as an example to explain the idea of Binomial Mixture Model. Please check my github for the python code.
Consider that we have 2 types of coins. The probability of getting a head when flipping the first type of coin is θ₁ = 0.5, while the probability of getting a head when flipping the second type of coin is θ₂ = 0.3. Say there are 10 coins in a bucket, 7 of them are the first type of coins, and 3 of them are the second type of coins. The two types of coins look identical, so we cannot tell which type a coin is by its appearance. We first blindly (randomly) pick one coin out of the bucket without knowing which type of coin it is. The chance of picking the first type is π₁ = 0.7, whereas the chance of picking the second type is π₂=0.3. After picking a coin from the bucket, we flip it a number of times (N), record the number of heads (n), and then put it back into the bucket. Then the probability of n is

where Θ refers to the set of parameters {π₁, θ₁, π₂, θ₂}. This formula can be easily extended to the case when there are K types of coins in the bucket. Then the probability of getting n heads is

In this case Θ refers to the set including all π_k and all θ_k. From now on, `_k` means that k is a subscript.
Now imagine we have a bucket containing K types of coins. We do not know the π’s or θ’s, meaning that we do not know Θ. We decide to carry out a series of experiments to find them out. In the ith experiment, we pick one coin from the bucket and flip it Nᵢ times, record the number of heads, nᵢ, and then put that coin back into the bucket. We do the experiment S times in total, so in the end, we get a list of (n,N) pairs, i.e. we observe the dataset = {(nᵢ, Nᵢ)| i =1,2,…,S}. Our goal is to find Θ which maximizes the likelihood of observing this list of pairs. Fitting a Binomial Mixture Model (BMM) with K binomial components would allow us to find Θ which fit the dataset reasonably.
Making the situation even more general, we do not know how many types of coins are in the bucket either, i.e. K is unknown as well. We will also discuss how to optimize K for a Binomial Mixture Model.
Expectation Maximization (EM) Algorithm
The task is to find the set of parameters, Θ, that maximizes the likelihood of observing the dataset, X = {(nᵢ, Nᵢ)| i =1,2,…,S}. The likelihood is defined as
L(Θ; X) = P(X|Θ),
which is the posterior probability of X given Θ. EM Algorithm is an iterative method that starts with a randomly chosen initial Θₒ and gradually shifts it to a final Θ that is reasonably optimal. This algorithm is named Expectation Maximization because its derivation contains two parts. In the first part, it shows that the log-likelihood, ln(L(Θ;X)), can be expressed as the Expectation of the complete-data log-likelihood. In the second part, it maximizes the Expectation of the complete-data log-likelihood, which leads to the formulas listed below. If you are interested in understanding the concept of complete-data log-likelihood and the derivations of the EM Algorithm, please read my note. Since it is math-heavy, I won’t show the derivations here. Instead, I only list the steps of the EM Algorithm below.
Step 1. Choose an initial Θₒ randomly. Make sure that the sum of all π’s is unity and every θ is between 0 and 1.
Step 2. Update Θ using the following formulas. Again, if you are interested in the derivations of them, please read my note.
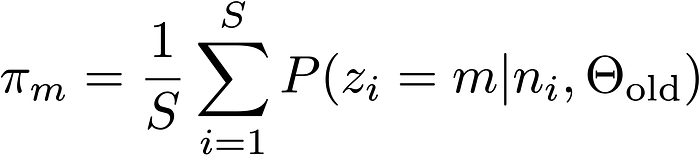
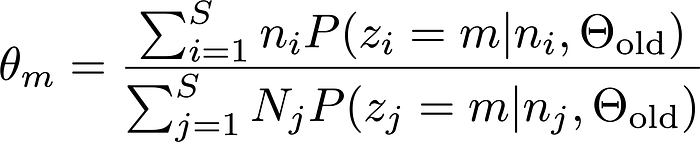
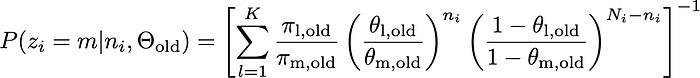
where the subscription
oldrefers to the Θ in the previous iterative step. The third equation provides the expression of the posterior probability for the i-th data point belonging to the m-th Binomial Distribution given nᵢ and the Θ_old.Step 3. Stop the iteration until some criterion is satisfied. For example, one can stop the iteration when the log-likelihood no longer improves by much within a single iteration. We provide the expression for the
log_likelihoodbelow,
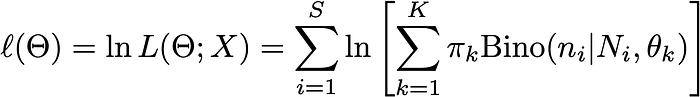
The stop condition may be
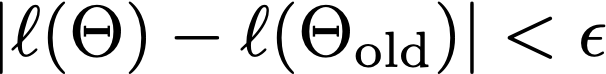
where ϵ is a small positive number, e.g. 0.1, 0.01, etc. One may also set up the maximum steps for the iteration
max_stepand force the iteration to stop if the criterion on thelog_likelihoodhas not yet been satisfied aftermax_steptimes of iterations.
By the end of the EM Algorithm iterations, one obtains the following outputs.
- { π_m|m=1,2,..,K} : the probability of each Binomial Distribution. When you pick one coin from the bucket blindly, π_m is the probability that this coin belonging to the m-th type of coins.
- {θ_m | m=1,2,…,K}: the probability of getting head when flipping a coin of the m-th type.
- {P(zᵢ=m|nᵢ, Θ) | m=1,..,K; i=1,…,S}: the probability that the coin picked in the i-th experiment belongs to the m-th type of coins, given the outcome of the i-th experiment, (nᵢ, Nᵢ).
log_likelihood: the natural-base logarithm of the probability of observing the dataset, X, given the parameters in Θ = {π_m, θ_m | m=1,2,…,K}. The higherlog_likelihood, the better the Binomial Mixture Model with parameters Θ represents the data.
Discussions
- One should adopt different random initializations for Θ, and see which one leads to the maximum
log_likelihood, because not every initialization may lead to the optimal Θ that maximizes thelog_likelihood. - In the case of unknown K, the number of types of coins, one may try K=1, K=2, K=3, K=4, etc, and plot the maximum
log_likelihoodas a function of K. Usually the maximumlog_likelihoodincreases with K. It first increases quickly (or sharply) with greater K for small K’s. Then after K goes beyond some K₀, the increasing rate oflog_likelihoodwith greater K slows down. Here K₀ is the elbow point and this K₀ is usually the optimal value for K which well balances the bias and variance of the BMM model.
